Edvancer's Knowledge Hub
Accelerate your job search with Word cloud in Python

Job search is a tedious process involving going through numerous job pages and lengthy job descriptions and summaries. In this article, I will try to make this process a bit easier for you using Python’s Beautiful Soup and Word cloud library.
We will extract information like job title, company name, location, job summary and description. All this information would be converted into a data frame to provide a concise view of all the job descriptions at one place, and later on we will put that info on word clouds.
Web Scraping using BeautifulSoup
Web scraping is the process of extracting data from websites. Web scraping a web page involves fetching the page and extracting data from it. Web pages are built using text-based mark-up languages such as HTML and XHTML. Beautiful Soup is a Python library for pulling data out of such HTML and XML files.
We are going to extract the following information from one of the most popular job search sites – indeed.com:
 Load all the required libraries and fetch the URL of the first and successive pages. Next, we will visit each page and extract their content. We are going to do that by calling Python’s urlopen().read() function from urllib package and parse the page by passing the content to BeautifulSoup function.
Fetch and store URL of all pages and parse the content
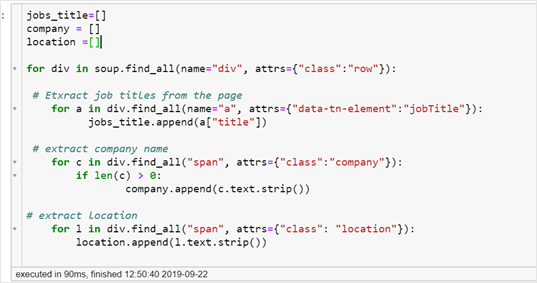
Now that we have content from all the pages, we are going to find, and store information related to Job title, Job location and Name of the company. To do so, right-click on a job listing and click on inspect to open the source code, and fetch the highlighted tags and their classes as shown in the code below.
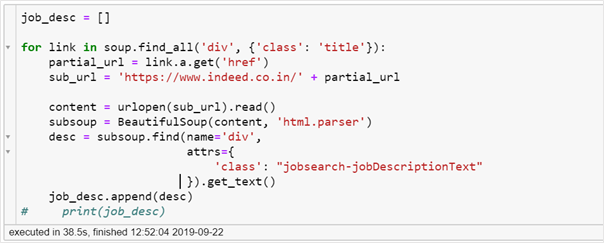
In order to get the job description for each job posting, we will find all the div tags with class title, and extract all the href links.
Append “https://www.indeed.com” to the beginning of each link because, in the source code of the page, all the hrefs are relative. If you click on the href link in the picture above, you would see the job listing in detail.
Visualise with World Cloud
We have all the information that we wanted for each job posting. Next, we will create word cloud using python’s wordcloud package and visualise using matplotlib library.
Word Cloud is a visual depiction of text data in which the size of each word indicates its frequency or importance. For instance, if we plot the Word cloud of job titles, the most common titles are displayed in a bigger size.
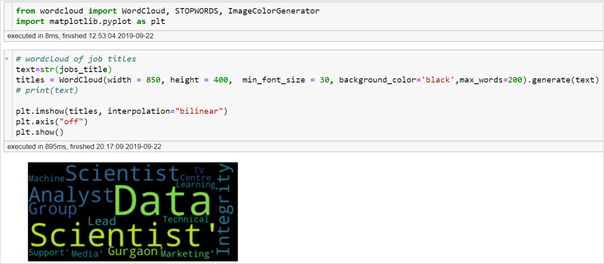
Word cloud of job titles
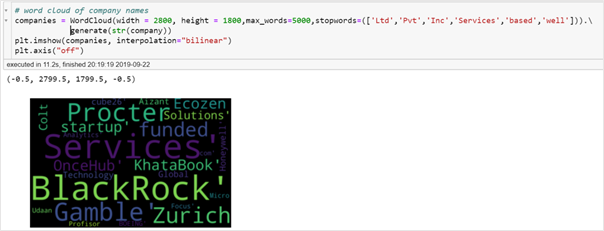
Word cloud of hiring Companies
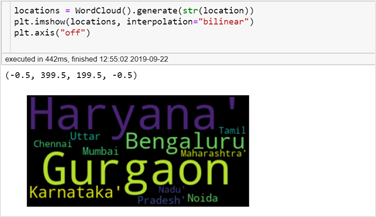
Word cloud of the locations of jobs posted @indeed
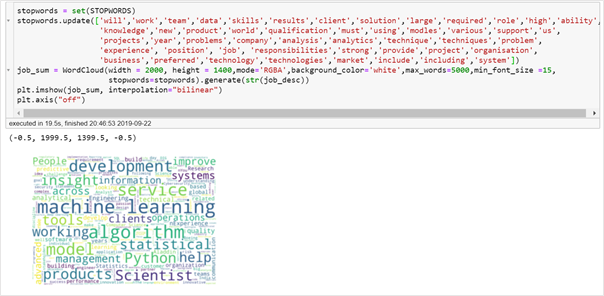
Word cloud of job descriptions
This is the simplest way to generate word clouds. There is a lot more that you can do with word clouds from here, you can play with different shape masks for the word cloud, or use advanced methods like TDIDF weighting technique.
Hope you liked reading this article.
Load all the required libraries and fetch the URL of the first and successive pages. Next, we will visit each page and extract their content. We are going to do that by calling Python’s urlopen().read() function from urllib package and parse the page by passing the content to BeautifulSoup function.
Fetch and store URL of all pages and parse the content
Now that we have content from all the pages, we are going to find, and store information related to Job title, Job location and Name of the company. To do so, right-click on a job listing and click on inspect to open the source code, and fetch the highlighted tags and their classes as shown in the code below.
In order to get the job description for each job posting, we will find all the div tags with class title, and extract all the href links.
Append “https://www.indeed.com” to the beginning of each link because, in the source code of the page, all the hrefs are relative. If you click on the href link in the picture above, you would see the job listing in detail.
Visualise with World Cloud
We have all the information that we wanted for each job posting. Next, we will create word cloud using python’s wordcloud package and visualise using matplotlib library.
Word Cloud is a visual depiction of text data in which the size of each word indicates its frequency or importance. For instance, if we plot the Word cloud of job titles, the most common titles are displayed in a bigger size.
Word cloud of job titles
Word cloud of hiring Companies
Word cloud of the locations of jobs posted @indeed
Word cloud of job descriptions
This is the simplest way to generate word clouds. There is a lot more that you can do with word clouds from here, you can play with different shape masks for the word cloud, or use advanced methods like TDIDF weighting technique.
Hope you liked reading this article.
Share this on
Follow us on
- Job title
- Job location
- Name of the company
- Job Description
- Gather URL of all the pages (numbered 1, 2,3 and so on at the bottom of each page)
- Access each URL and extract text
- Store the extracted data
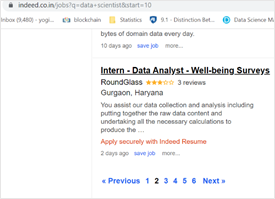
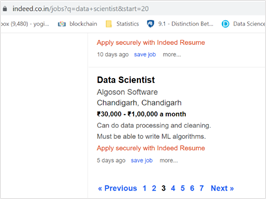 Load all the required libraries and fetch the URL of the first and successive pages. Next, we will visit each page and extract their content. We are going to do that by calling Python’s urlopen().read() function from urllib package and parse the page by passing the content to BeautifulSoup function.
Load all the required libraries and fetch the URL of the first and successive pages. Next, we will visit each page and extract their content. We are going to do that by calling Python’s urlopen().read() function from urllib package and parse the page by passing the content to BeautifulSoup function.
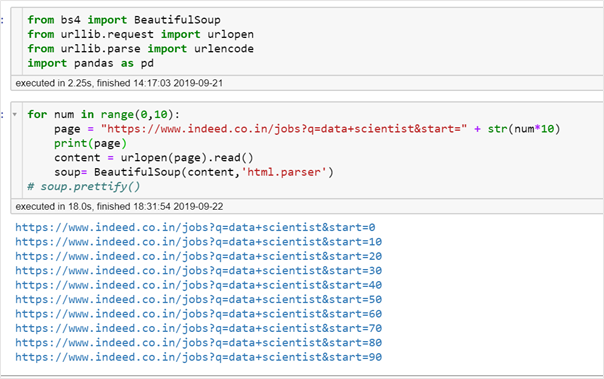 Fetch and store URL of all pages and parse the content
Now that we have content from all the pages, we are going to find, and store information related to Job title, Job location and Name of the company. To do so, right-click on a job listing and click on inspect to open the source code, and fetch the highlighted tags and their classes as shown in the code below.
Fetch and store URL of all pages and parse the content
Now that we have content from all the pages, we are going to find, and store information related to Job title, Job location and Name of the company. To do so, right-click on a job listing and click on inspect to open the source code, and fetch the highlighted tags and their classes as shown in the code below.
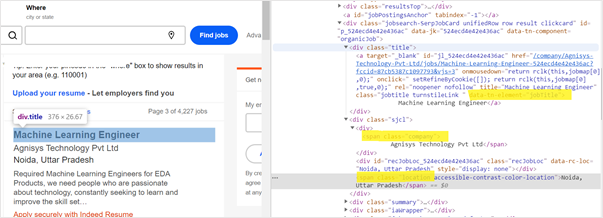
 In order to get the job description for each job posting, we will find all the div tags with class title, and extract all the href links.
In order to get the job description for each job posting, we will find all the div tags with class title, and extract all the href links.

 Append “https://www.indeed.com” to the beginning of each link because, in the source code of the page, all the hrefs are relative. If you click on the href link in the picture above, you would see the job listing in detail.
Visualise with World Cloud
We have all the information that we wanted for each job posting. Next, we will create word cloud using python’s wordcloud package and visualise using matplotlib library.
Word Cloud is a visual depiction of text data in which the size of each word indicates its frequency or importance. For instance, if we plot the Word cloud of job titles, the most common titles are displayed in a bigger size.
Word cloud of job titles
Append “https://www.indeed.com” to the beginning of each link because, in the source code of the page, all the hrefs are relative. If you click on the href link in the picture above, you would see the job listing in detail.
Visualise with World Cloud
We have all the information that we wanted for each job posting. Next, we will create word cloud using python’s wordcloud package and visualise using matplotlib library.
Word Cloud is a visual depiction of text data in which the size of each word indicates its frequency or importance. For instance, if we plot the Word cloud of job titles, the most common titles are displayed in a bigger size.
Word cloud of job titles
 Word cloud of hiring Companies
Word cloud of hiring Companies
 Word cloud of the locations of jobs posted @indeed
Word cloud of the locations of jobs posted @indeed
 Word cloud of job descriptions
Word cloud of job descriptions
 This is the simplest way to generate word clouds. There is a lot more that you can do with word clouds from here, you can play with different shape masks for the word cloud, or use advanced methods like TDIDF weighting technique.
Hope you liked reading this article.
This is the simplest way to generate word clouds. There is a lot more that you can do with word clouds from here, you can play with different shape masks for the word cloud, or use advanced methods like TDIDF weighting technique.
Hope you liked reading this article.
Latest posts by Yogita Kinha (see all)
- A simple guide to Hypothesis Testing - September 24, 2019
- Accelerate your job search with Word cloud in Python - September 22, 2019
- AI revolution in Healthcare industry - September 8, 2019
Follow us on
Free Data Science & AI Starter Course
