Edvancer's Knowledge Hub
How to approach a data science problem (part 2)

This blog post is a continuation of the previous one on the same topic.
Let’s begin on the data side. While model building, you skip over the phases of transport, store and secure, as you take a batch of useful data, based on your assumptions, and try to test some hypothesis about it. For example, let’s take analyzing data from different networks. Through some grouping and clustering of your trouble ticket data, you may see many issues on your network router with a specific version of the software.
In this case, you can form an analysis that proves your theory that the problems are in fact related to the version of software that is running on the suspect network routers. For the data first approach, you need to decide on the problems you want to solve. You also need to use data to guide you to what is possible, based on your knowledge of the environment.
What do you need in the example of the suspect routers? Clearly, you must obtain data about the network routers when they showed the issue, as well as data about the same types of routers that have not exhibited that issue. You require both of these types of information to find the underlying factors that may or may not have added to the issue you are researching. Discovering these factors is a form of inference, as you would like to infer something about all of your routers, based on comparisons of differences in a set of devices that exhibit the issue and a set of devices that do not. You will later use the same analytics model for prediction.
You can normally skip the “production data” acquisition and transport parts of the model building phase. Although in this case you have a data set to work with for your analysis, consider here how to automate the acquisition of data, how to transport it, and where it will live if you plan to put your model into a fully automated production state so it can notify you of devices in the network that meet these criteria. On the other hand, full production state is not always essential. Sometimes you can just take a batch of data and run it against something on your own machine to get insights; this is valid and common. Sometimes you can accumulate sufficient data about a problem to solve it, and you can obtain insight without having to employ a full production system.
In a diametrically opposite manner, a common analyst approach is to begin with a known problem and determine what data is necessary to solve that problem. You often have to seek things that you don’t know to look for. Think about this example: Maybe you have customers with service-level agreements (SLAs), and you realize that you are giving them discounts because they are having voice issues over the network and you are not meeting the SLAs. This is costing your company money. You delve into what you need to analyze so as to understand why this happens, perhaps using voice drop and latency data from your environment. When you finally get the data, you make a proposed model that identifies that higher latency with particular versions of software on network routers is common on devices in the network path for customers who are asking for refunds. Then you deploy the model to flag these “SLA suckers” in your production systems and then confirm that the model is effective as the SLA issues have gone away. In this case, deploy means that your model is examining your daily inventory data and searching for a device that matches the parameters that you have seen are problematic. What may have been a very complex model has a simple deployment.
Whether you are starting at data or at a business problem, eventually, solving the problem represents the value to your company and to you as an analyst. Both approaches follow a lot of the same steps on the journey of analytics, but frequently use different terminology. They are both about turning data into value, irrespective of starting point, direction, or approach. Figure 3 provides a more exhaustive perspective that illustrates that these two approaches can work in the same environment on the same data and the exact same problem statement. In simpler terms, all of the work and due diligence needs to be done to have a fully operational (with models built, tested, and deployed), end-to-end use case that provides real, continuous value.
 Figure 3: Detailed Comparison of Data Versus Problem Approaches
The industry today offers a wide range of detailed approaches and frameworks, such as CRISP-DM (Cross-Industry Standard Process for Data Mining) and SEMMA (Sample Explore, Modify, Model, and Assess), and they all usually follow these same principles. Select something that matches your style and roll with it. Regardless of your approach, the primary goal is to create useful solutions in your problem space by merging the data you have with data science techniques to develop use cases that bring insights to the forefront.
Distinction Between the Use Case and the Solution
Before we go further, let’s simplify a few terms. Basically, a use case is a description of a problem that you solve by combining data and data science and applying analytics. The underlying algorithms and models constitute the actual analytics solution. Taking the case of Amazon as an example, the use case is getting you to spend more money. Amazon does this by showing you what other people have also purchased along with the item that you are purchasing. The thought behind this is that you will buy more things because other people like you needed those things when they bought the same item that you did. The model is there to uncover that and convey to you that you may also need to purchase those other things. Quite helpful, right?
From the exploratory data approach, Amazon might want to utilize the data it has about what people are buying online. It can then accumulate the high patterns of common sets of purchases. Then, for patterns that are close but missing just a few items, Amazon might assume that those people simply “forgot” to purchase something they needed because everyone else purchased the complete “item set” found in the data. Amazon might then use software implementation to find the people who “forgot” and remind them that they might require the other common items. Then Amazon can validate the effectiveness by tracking purchases of items that the model suggested.
From a business problem approach, Amazon might want to increase sales, and it might assume, or find research suggesting that if people are reminded about the common companion items to the items they are currently viewing or have added to their shopping carts, they often purchase these items. In order to execute this, Amazon might gather buying pattern data to find out these companion items. The company might then propose that people may also want to purchase these items. Amazon can then validate the effectiveness by tracking purchases of suggested items.
Do you see how both these approaches reach the same final solution?
The Amazon case is about increasing sales of items. In predictive analytics, the use case may be about predicting home values or car values. Simply put, the use case may be the ability to predict a continuous number from historical numbers. No matter the use case, you can basically view analytics as the application of data and data science to the problem domain. You can choose how you want to approach finding and building the solutions-either by using the data as a guide or by dissecting the stated problem.
Figure 3: Detailed Comparison of Data Versus Problem Approaches
The industry today offers a wide range of detailed approaches and frameworks, such as CRISP-DM (Cross-Industry Standard Process for Data Mining) and SEMMA (Sample Explore, Modify, Model, and Assess), and they all usually follow these same principles. Select something that matches your style and roll with it. Regardless of your approach, the primary goal is to create useful solutions in your problem space by merging the data you have with data science techniques to develop use cases that bring insights to the forefront.
Distinction Between the Use Case and the Solution
Before we go further, let’s simplify a few terms. Basically, a use case is a description of a problem that you solve by combining data and data science and applying analytics. The underlying algorithms and models constitute the actual analytics solution. Taking the case of Amazon as an example, the use case is getting you to spend more money. Amazon does this by showing you what other people have also purchased along with the item that you are purchasing. The thought behind this is that you will buy more things because other people like you needed those things when they bought the same item that you did. The model is there to uncover that and convey to you that you may also need to purchase those other things. Quite helpful, right?
From the exploratory data approach, Amazon might want to utilize the data it has about what people are buying online. It can then accumulate the high patterns of common sets of purchases. Then, for patterns that are close but missing just a few items, Amazon might assume that those people simply “forgot” to purchase something they needed because everyone else purchased the complete “item set” found in the data. Amazon might then use software implementation to find the people who “forgot” and remind them that they might require the other common items. Then Amazon can validate the effectiveness by tracking purchases of items that the model suggested.
From a business problem approach, Amazon might want to increase sales, and it might assume, or find research suggesting that if people are reminded about the common companion items to the items they are currently viewing or have added to their shopping carts, they often purchase these items. In order to execute this, Amazon might gather buying pattern data to find out these companion items. The company might then propose that people may also want to purchase these items. Amazon can then validate the effectiveness by tracking purchases of suggested items.
Do you see how both these approaches reach the same final solution?
The Amazon case is about increasing sales of items. In predictive analytics, the use case may be about predicting home values or car values. Simply put, the use case may be the ability to predict a continuous number from historical numbers. No matter the use case, you can basically view analytics as the application of data and data science to the problem domain. You can choose how you want to approach finding and building the solutions-either by using the data as a guide or by dissecting the stated problem.

Share this on
Follow us on
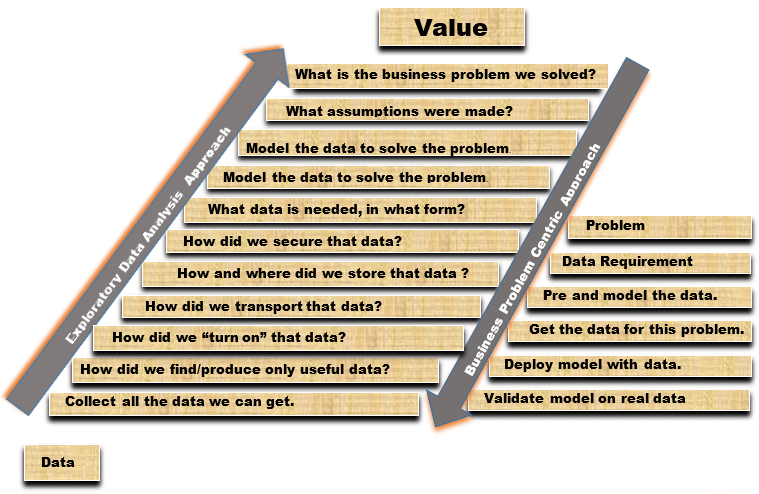 Figure 3: Detailed Comparison of Data Versus Problem Approaches
The industry today offers a wide range of detailed approaches and frameworks, such as CRISP-DM (Cross-Industry Standard Process for Data Mining) and SEMMA (Sample Explore, Modify, Model, and Assess), and they all usually follow these same principles. Select something that matches your style and roll with it. Regardless of your approach, the primary goal is to create useful solutions in your problem space by merging the data you have with data science techniques to develop use cases that bring insights to the forefront.
Distinction Between the Use Case and the Solution
Before we go further, let’s simplify a few terms. Basically, a use case is a description of a problem that you solve by combining data and data science and applying analytics. The underlying algorithms and models constitute the actual analytics solution. Taking the case of Amazon as an example, the use case is getting you to spend more money. Amazon does this by showing you what other people have also purchased along with the item that you are purchasing. The thought behind this is that you will buy more things because other people like you needed those things when they bought the same item that you did. The model is there to uncover that and convey to you that you may also need to purchase those other things. Quite helpful, right?
From the exploratory data approach, Amazon might want to utilize the data it has about what people are buying online. It can then accumulate the high patterns of common sets of purchases. Then, for patterns that are close but missing just a few items, Amazon might assume that those people simply “forgot” to purchase something they needed because everyone else purchased the complete “item set” found in the data. Amazon might then use software implementation to find the people who “forgot” and remind them that they might require the other common items. Then Amazon can validate the effectiveness by tracking purchases of items that the model suggested.
From a business problem approach, Amazon might want to increase sales, and it might assume, or find research suggesting that if people are reminded about the common companion items to the items they are currently viewing or have added to their shopping carts, they often purchase these items. In order to execute this, Amazon might gather buying pattern data to find out these companion items. The company might then propose that people may also want to purchase these items. Amazon can then validate the effectiveness by tracking purchases of suggested items.
Do you see how both these approaches reach the same final solution?
The Amazon case is about increasing sales of items. In predictive analytics, the use case may be about predicting home values or car values. Simply put, the use case may be the ability to predict a continuous number from historical numbers. No matter the use case, you can basically view analytics as the application of data and data science to the problem domain. You can choose how you want to approach finding and building the solutions-either by using the data as a guide or by dissecting the stated problem.
Figure 3: Detailed Comparison of Data Versus Problem Approaches
The industry today offers a wide range of detailed approaches and frameworks, such as CRISP-DM (Cross-Industry Standard Process for Data Mining) and SEMMA (Sample Explore, Modify, Model, and Assess), and they all usually follow these same principles. Select something that matches your style and roll with it. Regardless of your approach, the primary goal is to create useful solutions in your problem space by merging the data you have with data science techniques to develop use cases that bring insights to the forefront.
Distinction Between the Use Case and the Solution
Before we go further, let’s simplify a few terms. Basically, a use case is a description of a problem that you solve by combining data and data science and applying analytics. The underlying algorithms and models constitute the actual analytics solution. Taking the case of Amazon as an example, the use case is getting you to spend more money. Amazon does this by showing you what other people have also purchased along with the item that you are purchasing. The thought behind this is that you will buy more things because other people like you needed those things when they bought the same item that you did. The model is there to uncover that and convey to you that you may also need to purchase those other things. Quite helpful, right?
From the exploratory data approach, Amazon might want to utilize the data it has about what people are buying online. It can then accumulate the high patterns of common sets of purchases. Then, for patterns that are close but missing just a few items, Amazon might assume that those people simply “forgot” to purchase something they needed because everyone else purchased the complete “item set” found in the data. Amazon might then use software implementation to find the people who “forgot” and remind them that they might require the other common items. Then Amazon can validate the effectiveness by tracking purchases of items that the model suggested.
From a business problem approach, Amazon might want to increase sales, and it might assume, or find research suggesting that if people are reminded about the common companion items to the items they are currently viewing or have added to their shopping carts, they often purchase these items. In order to execute this, Amazon might gather buying pattern data to find out these companion items. The company might then propose that people may also want to purchase these items. Amazon can then validate the effectiveness by tracking purchases of suggested items.
Do you see how both these approaches reach the same final solution?
The Amazon case is about increasing sales of items. In predictive analytics, the use case may be about predicting home values or car values. Simply put, the use case may be the ability to predict a continuous number from historical numbers. No matter the use case, you can basically view analytics as the application of data and data science to the problem domain. You can choose how you want to approach finding and building the solutions-either by using the data as a guide or by dissecting the stated problem.
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
