Edvancer's Knowledge Hub
How can an engineering fresher get into analytics? [Part 2]

This article is a continuation of my previous article on the same topic. In this post, we will elaborate on how a fresh engineering graduate can take the path of a Big Data Engineer.
What does a Data Engineer and a Data Architect do?
A Data Engineer compiles and installs database systems, writes complex database queries, scales it to multiple machines, ensures backups and puts disaster recovery systems in place. They have a deep knowledge and expertise in one or more database software systems (SQL / NoSQL).
They build a robust Data pipeline that cleans, transforms, and aggregates complex and messy data sets into databases or data sources, so that the Data Scientists or Analysts can use this data for analysis.
Data Engineers essentially lay the groundwork for a Data Analyst or a Data Scientist to retrieve the required data for their evaluations and experiments with ease. In other words, Data Scientists extract value from data, whereas, Data Engineers ensure that the data flows smoothly from source to destination so that it is processed.
 Enterprises have a huge amount of internal data (web analytics, CRM, HRMS, etc) and external data (social media, third party sources) sources.
After assessing a company’s potential data sources, a Data Architect creates an end plan to integrate, centralize, protect and maintain them. He understands how these potential data sources relate to the current business operations, and how they are scalable according to the future business needs. The plan he lays will show how the data will flow through the different stages of the Data pipeline. This may include things like designing relational databases, developing strategies for data acquisitions, archive recovery, and implementation of a database, cleaning and maintaining the database by removing and deleting old data etc.
Now, I will discuss about the skill sets required to get an entry-level job as a data engineer,
Skill Sets of a Data Engineer
Programming
Data engineers are software developers who build data products. If you want to take this path then you should learn Python and Java. Big Data is generally developed using technologies like Java, hence you must know Java. Python is very versatile and allows Data Engineers to maintain a high velocity across all of the work they need to do. For example, a Data Engineer can use Python to automate a data pull from a FTP site, use Pandas to clean and transform it, use Boto to upload it to the server.
SQL and NoSQL
In the world of database technology, there are two main types of databases: SQL and NoSQL—or, relational databases and non-relational databases. The difference speaks to how they are built, the type of information they store, and how they store it. Relational databases are structured; like phone books that store phone numbers and addresses. Non-relational databases are document-oriented and distributed, like file folders that hold everything from a person’s address and phone number to their facebook likes and online shopping preferences.
Source: Microsoft
Today, the database landscape continues to become increasingly complicated. The usual SQL suspects—SQL Server-Oracle-DB2-Postgres, et al.—are not handling this new world on their own, and some say they cannot. However, the division between SQL and NoSQL is increasingly fuzzy, especially as data engineers integrate the technologies together and add bits of one to the other.
You need to have a good understanding of SQL and NoSQL systems to become a Data Engineer.
Hadoop ecosystem
Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop is enabled by a technology created by Google called Map Reduce, a way to process and generate large data sets with a parallel, distributed algorithm on a cluster.
We have already given a simple explanation of the Hadoop ecosystem in this blog post.
You must be familiar with the tools associated with Hadoop like Hive, Pig, Oozie, Mahout, etc.
Some of the Hadoop companies like Cloudera and Hortonworks are making cluster administration easier with web-based GUIs. You need to know how to install and implement packages in a cloud system.
Linux and cloud computing
To save cost, companies host their databases on cloud platforms.And more than 25% of servers powering Azure are Linux based, a percentage that is only set to grow as Microsoft continues to embrace the open-source market. Businesses are increasingly on the hunt for professionals with the skills to design, build, administer and maintain Linux servers in a cloud environment.
Conclusion
Data pipeline projects require different Big Data technologies working together. Each of those technologies needs a level of expertise. There is a vast amount of variance in how difficult each one is to learn.
People new to Data Engineering are generally involved in vendor marketing. Their marketing message is about learning a specific technology, which might be Spark, Hadoop, or some other technology.
The message that people come away with is that simply learning one of these technologies will make you a Data Engineer. The sad truth is that they are completely wrong and will waste copious amounts of time.
Big Data vendor marketing is targeting enterprises, not individuals. They are targeting teams that need to add a specific toolset to their group, or companies are taking a series of classes to transform their team of Software Developers into Data Engineers.
Individuals have to do the same thing. They will need to master several different technologies in order to get a job as a Data Engineer. This is what companies are looking for. They are looking for Data Engineers who can create complex Data Pipelines.
To become a Data Engineer, you must have the right blend knowledge of Python, Java, Hadoop, Cloud Computing, SQL and NoSQL.
Enterprises have a huge amount of internal data (web analytics, CRM, HRMS, etc) and external data (social media, third party sources) sources.
After assessing a company’s potential data sources, a Data Architect creates an end plan to integrate, centralize, protect and maintain them. He understands how these potential data sources relate to the current business operations, and how they are scalable according to the future business needs. The plan he lays will show how the data will flow through the different stages of the Data pipeline. This may include things like designing relational databases, developing strategies for data acquisitions, archive recovery, and implementation of a database, cleaning and maintaining the database by removing and deleting old data etc.
Now, I will discuss about the skill sets required to get an entry-level job as a data engineer,
Skill Sets of a Data Engineer
Programming
Data engineers are software developers who build data products. If you want to take this path then you should learn Python and Java. Big Data is generally developed using technologies like Java, hence you must know Java. Python is very versatile and allows Data Engineers to maintain a high velocity across all of the work they need to do. For example, a Data Engineer can use Python to automate a data pull from a FTP site, use Pandas to clean and transform it, use Boto to upload it to the server.
SQL and NoSQL
In the world of database technology, there are two main types of databases: SQL and NoSQL—or, relational databases and non-relational databases. The difference speaks to how they are built, the type of information they store, and how they store it. Relational databases are structured; like phone books that store phone numbers and addresses. Non-relational databases are document-oriented and distributed, like file folders that hold everything from a person’s address and phone number to their facebook likes and online shopping preferences.
Source: Microsoft
Today, the database landscape continues to become increasingly complicated. The usual SQL suspects—SQL Server-Oracle-DB2-Postgres, et al.—are not handling this new world on their own, and some say they cannot. However, the division between SQL and NoSQL is increasingly fuzzy, especially as data engineers integrate the technologies together and add bits of one to the other.
You need to have a good understanding of SQL and NoSQL systems to become a Data Engineer.
Hadoop ecosystem
Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop is enabled by a technology created by Google called Map Reduce, a way to process and generate large data sets with a parallel, distributed algorithm on a cluster.
We have already given a simple explanation of the Hadoop ecosystem in this blog post.
You must be familiar with the tools associated with Hadoop like Hive, Pig, Oozie, Mahout, etc.
Some of the Hadoop companies like Cloudera and Hortonworks are making cluster administration easier with web-based GUIs. You need to know how to install and implement packages in a cloud system.
Linux and cloud computing
To save cost, companies host their databases on cloud platforms.And more than 25% of servers powering Azure are Linux based, a percentage that is only set to grow as Microsoft continues to embrace the open-source market. Businesses are increasingly on the hunt for professionals with the skills to design, build, administer and maintain Linux servers in a cloud environment.
Conclusion
Data pipeline projects require different Big Data technologies working together. Each of those technologies needs a level of expertise. There is a vast amount of variance in how difficult each one is to learn.
People new to Data Engineering are generally involved in vendor marketing. Their marketing message is about learning a specific technology, which might be Spark, Hadoop, or some other technology.
The message that people come away with is that simply learning one of these technologies will make you a Data Engineer. The sad truth is that they are completely wrong and will waste copious amounts of time.
Big Data vendor marketing is targeting enterprises, not individuals. They are targeting teams that need to add a specific toolset to their group, or companies are taking a series of classes to transform their team of Software Developers into Data Engineers.
Individuals have to do the same thing. They will need to master several different technologies in order to get a job as a Data Engineer. This is what companies are looking for. They are looking for Data Engineers who can create complex Data Pipelines.
To become a Data Engineer, you must have the right blend knowledge of Python, Java, Hadoop, Cloud Computing, SQL and NoSQL.

Share this on
Follow us on
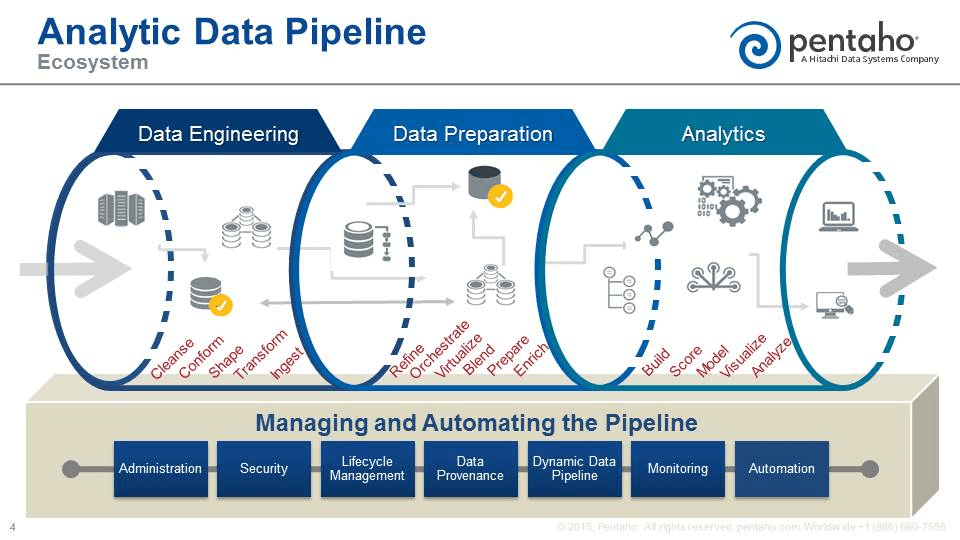 Enterprises have a huge amount of internal data (web analytics, CRM, HRMS, etc) and external data (social media, third party sources) sources.
After assessing a company’s potential data sources, a Data Architect creates an end plan to integrate, centralize, protect and maintain them. He understands how these potential data sources relate to the current business operations, and how they are scalable according to the future business needs. The plan he lays will show how the data will flow through the different stages of the Data pipeline. This may include things like designing relational databases, developing strategies for data acquisitions, archive recovery, and implementation of a database, cleaning and maintaining the database by removing and deleting old data etc.
Now, I will discuss about the skill sets required to get an entry-level job as a data engineer,
Skill Sets of a Data Engineer
Programming
Data engineers are software developers who build data products. If you want to take this path then you should learn Python and Java. Big Data is generally developed using technologies like Java, hence you must know Java. Python is very versatile and allows Data Engineers to maintain a high velocity across all of the work they need to do. For example, a Data Engineer can use Python to automate a data pull from a FTP site, use Pandas to clean and transform it, use Boto to upload it to the server.
SQL and NoSQL
In the world of database technology, there are two main types of databases: SQL and NoSQL—or, relational databases and non-relational databases. The difference speaks to how they are built, the type of information they store, and how they store it. Relational databases are structured; like phone books that store phone numbers and addresses. Non-relational databases are document-oriented and distributed, like file folders that hold everything from a person’s address and phone number to their facebook likes and online shopping preferences.
Enterprises have a huge amount of internal data (web analytics, CRM, HRMS, etc) and external data (social media, third party sources) sources.
After assessing a company’s potential data sources, a Data Architect creates an end plan to integrate, centralize, protect and maintain them. He understands how these potential data sources relate to the current business operations, and how they are scalable according to the future business needs. The plan he lays will show how the data will flow through the different stages of the Data pipeline. This may include things like designing relational databases, developing strategies for data acquisitions, archive recovery, and implementation of a database, cleaning and maintaining the database by removing and deleting old data etc.
Now, I will discuss about the skill sets required to get an entry-level job as a data engineer,
Skill Sets of a Data Engineer
Programming
Data engineers are software developers who build data products. If you want to take this path then you should learn Python and Java. Big Data is generally developed using technologies like Java, hence you must know Java. Python is very versatile and allows Data Engineers to maintain a high velocity across all of the work they need to do. For example, a Data Engineer can use Python to automate a data pull from a FTP site, use Pandas to clean and transform it, use Boto to upload it to the server.
SQL and NoSQL
In the world of database technology, there are two main types of databases: SQL and NoSQL—or, relational databases and non-relational databases. The difference speaks to how they are built, the type of information they store, and how they store it. Relational databases are structured; like phone books that store phone numbers and addresses. Non-relational databases are document-oriented and distributed, like file folders that hold everything from a person’s address and phone number to their facebook likes and online shopping preferences.
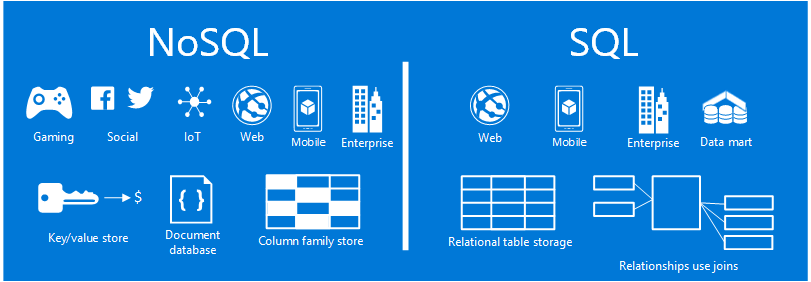 Source: Microsoft
Today, the database landscape continues to become increasingly complicated. The usual SQL suspects—SQL Server-Oracle-DB2-Postgres, et al.—are not handling this new world on their own, and some say they cannot. However, the division between SQL and NoSQL is increasingly fuzzy, especially as data engineers integrate the technologies together and add bits of one to the other.
You need to have a good understanding of SQL and NoSQL systems to become a Data Engineer.
Hadoop ecosystem
Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop is enabled by a technology created by Google called Map Reduce, a way to process and generate large data sets with a parallel, distributed algorithm on a cluster.
We have already given a simple explanation of the Hadoop ecosystem in this blog post.
Source: Microsoft
Today, the database landscape continues to become increasingly complicated. The usual SQL suspects—SQL Server-Oracle-DB2-Postgres, et al.—are not handling this new world on their own, and some say they cannot. However, the division between SQL and NoSQL is increasingly fuzzy, especially as data engineers integrate the technologies together and add bits of one to the other.
You need to have a good understanding of SQL and NoSQL systems to become a Data Engineer.
Hadoop ecosystem
Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop is enabled by a technology created by Google called Map Reduce, a way to process and generate large data sets with a parallel, distributed algorithm on a cluster.
We have already given a simple explanation of the Hadoop ecosystem in this blog post.
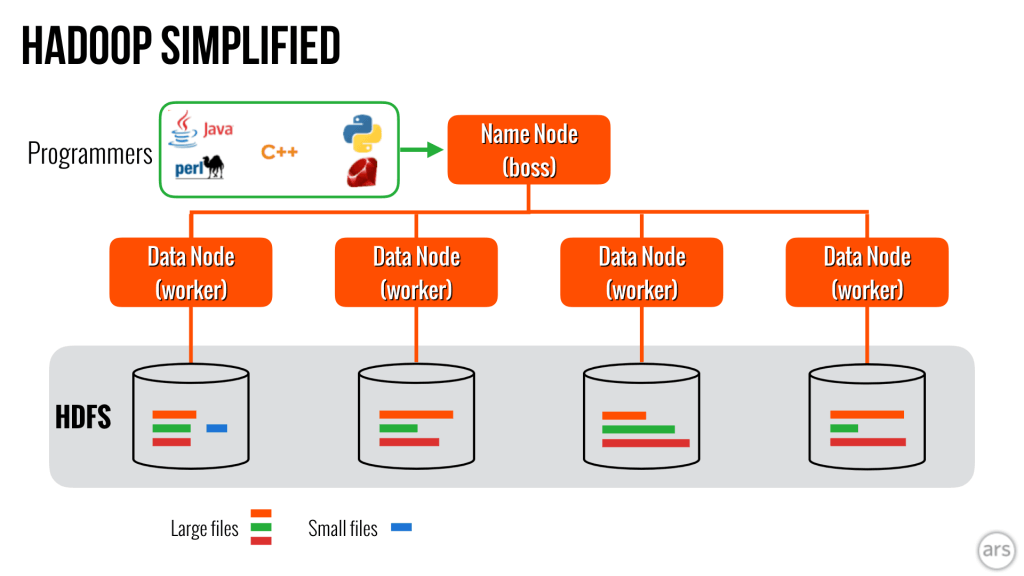 You must be familiar with the tools associated with Hadoop like Hive, Pig, Oozie, Mahout, etc.
Some of the Hadoop companies like Cloudera and Hortonworks are making cluster administration easier with web-based GUIs. You need to know how to install and implement packages in a cloud system.
Linux and cloud computing
To save cost, companies host their databases on cloud platforms.And more than 25% of servers powering Azure are Linux based, a percentage that is only set to grow as Microsoft continues to embrace the open-source market. Businesses are increasingly on the hunt for professionals with the skills to design, build, administer and maintain Linux servers in a cloud environment.
Conclusion
Data pipeline projects require different Big Data technologies working together. Each of those technologies needs a level of expertise. There is a vast amount of variance in how difficult each one is to learn.
People new to Data Engineering are generally involved in vendor marketing. Their marketing message is about learning a specific technology, which might be Spark, Hadoop, or some other technology.
The message that people come away with is that simply learning one of these technologies will make you a Data Engineer. The sad truth is that they are completely wrong and will waste copious amounts of time.
Big Data vendor marketing is targeting enterprises, not individuals. They are targeting teams that need to add a specific toolset to their group, or companies are taking a series of classes to transform their team of Software Developers into Data Engineers.
Individuals have to do the same thing. They will need to master several different technologies in order to get a job as a Data Engineer. This is what companies are looking for. They are looking for Data Engineers who can create complex Data Pipelines.
To become a Data Engineer, you must have the right blend knowledge of Python, Java, Hadoop, Cloud Computing, SQL and NoSQL.
You must be familiar with the tools associated with Hadoop like Hive, Pig, Oozie, Mahout, etc.
Some of the Hadoop companies like Cloudera and Hortonworks are making cluster administration easier with web-based GUIs. You need to know how to install and implement packages in a cloud system.
Linux and cloud computing
To save cost, companies host their databases on cloud platforms.And more than 25% of servers powering Azure are Linux based, a percentage that is only set to grow as Microsoft continues to embrace the open-source market. Businesses are increasingly on the hunt for professionals with the skills to design, build, administer and maintain Linux servers in a cloud environment.
Conclusion
Data pipeline projects require different Big Data technologies working together. Each of those technologies needs a level of expertise. There is a vast amount of variance in how difficult each one is to learn.
People new to Data Engineering are generally involved in vendor marketing. Their marketing message is about learning a specific technology, which might be Spark, Hadoop, or some other technology.
The message that people come away with is that simply learning one of these technologies will make you a Data Engineer. The sad truth is that they are completely wrong and will waste copious amounts of time.
Big Data vendor marketing is targeting enterprises, not individuals. They are targeting teams that need to add a specific toolset to their group, or companies are taking a series of classes to transform their team of Software Developers into Data Engineers.
Individuals have to do the same thing. They will need to master several different technologies in order to get a job as a Data Engineer. This is what companies are looking for. They are looking for Data Engineers who can create complex Data Pipelines.
To become a Data Engineer, you must have the right blend knowledge of Python, Java, Hadoop, Cloud Computing, SQL and NoSQL.
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
