Edvancer's Knowledge Hub
Hadoop Explained Simply!

We live in the data age. IDC has forecasted that one billion terabytes of data will be generated by 2020.
This flood of data is coming from various sources.
 Source:Pivotal.io
“HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.” Hadoop by default stores 3 copies of each data block in the cluster on different nodes of the cluster. Any time a node or machine fails containing a certain block of data, another copy is created on another node in the cluster thus making the system fail proof.
Let me explain this statement.
“Very large” in this context means files that are hundreds of megabytes, gigabytes or terabytes in size. There are Hadoop clusters running today that store petabytes of data.
“Streaming data access.”
HDFS follows a write-once and read-many-times pattern. A dataset is generated or copied from the source, and then various analysis is performed on the dataset. Each analysis will involve a large proportion of the dataset, if not all, of the dataset, so the time to read the whole dataset is important than the latency (delay from the input into a system to the desired outcome) in reading the first record.
“Commodity hardware.”
Hadoop doesn’t require expensive hardware. It is designed to run on clusters of commodity hardware (a commonly available hardware that can be purchased from multiple vendors for which the chance of node failure across the cluster is high, at least for large clusters. HDFS is designed to handle such node failures.
Source: DME
MapReduce enables anyone with access to the cluster to perform large-scale data analysis. Mapreduce has another benefit in that it moves the computing algorithm to where the data is stored instead of moving the data to the place where the computation has to occur. This saves tremendous amount of time and bandwidth which would have been spent in moving the tons of data from storage to computation.
MapReduce is a good fit for problems that need to analyze the whole dataset in a batch fashion, but it is not suitable for interactive analysis – you can’t run a query and get back answers in a few seconds or less. Responses to queries can take minutes or more, so MapReduce is better for offline use (where a human isn’t waiting for the answer to the queries).
Source:Pivotal.io
“HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.” Hadoop by default stores 3 copies of each data block in the cluster on different nodes of the cluster. Any time a node or machine fails containing a certain block of data, another copy is created on another node in the cluster thus making the system fail proof.
Let me explain this statement.
“Very large” in this context means files that are hundreds of megabytes, gigabytes or terabytes in size. There are Hadoop clusters running today that store petabytes of data.
“Streaming data access.”
HDFS follows a write-once and read-many-times pattern. A dataset is generated or copied from the source, and then various analysis is performed on the dataset. Each analysis will involve a large proportion of the dataset, if not all, of the dataset, so the time to read the whole dataset is important than the latency (delay from the input into a system to the desired outcome) in reading the first record.
“Commodity hardware.”
Hadoop doesn’t require expensive hardware. It is designed to run on clusters of commodity hardware (a commonly available hardware that can be purchased from multiple vendors for which the chance of node failure across the cluster is high, at least for large clusters. HDFS is designed to handle such node failures.
Source: DME
MapReduce enables anyone with access to the cluster to perform large-scale data analysis. Mapreduce has another benefit in that it moves the computing algorithm to where the data is stored instead of moving the data to the place where the computation has to occur. This saves tremendous amount of time and bandwidth which would have been spent in moving the tons of data from storage to computation.
MapReduce is a good fit for problems that need to analyze the whole dataset in a batch fashion, but it is not suitable for interactive analysis – you can’t run a query and get back answers in a few seconds or less. Responses to queries can take minutes or more, so MapReduce is better for offline use (where a human isn’t waiting for the answer to the queries).
Share this on
Follow us on
- New York stock exchange generates about 4-5 terabytes of data every day.
- Facebook hosts more than 240 billion photos, growing at seven petabytes per month.
- The internet archive stores around 5 petabytes of data.
Data Storage and Analysis
The problem is simple. Even though the storage capacity of hard drives has increased dramatically over the years, access speeds – the rate at which data can be read from the drives – have not kept up. In the 1990s, one typical drive could store 1,370 MB of data and had a transfer speed of 4.4MB/s. So you could read all the data from a full drive in approximately five minutes. In 2015, one typical drive could store one terabyte of data, and the transfer speed is around 100 MB/s. So it takes two and half hours to read all the data off the drive – this is a long time to read all the data on a single drive. An easy way to reduce the time is to read data simultaneously from multiple disks. Let’s say, you have 100 drives, each holding one hundredth of the data. Working in parallel, you could read the data in around two minutes. Since, using only one hundredth of the data is not economical we can store 100 datasets, each of which is one terabyte, and provide shared access to them. This will reduce the time to read and write data significantly. But there are two major problems when multiple disks are connected in parallel. Let’s see what those problems are.Hadoop File System Explained
The first problem is that the chances of a hardware failure are high (as you are using a lot of hardware, the chance that one will fail is fairly high). A common way to avoid loss of data is to take a backup of data in the system. So that in the event of failure, there is another copy of data available. This is how RAID works, but HDFS (Hadoop distributed file system) takes a slightly different approach. Hadoop comes with a distributed file system called HDFS.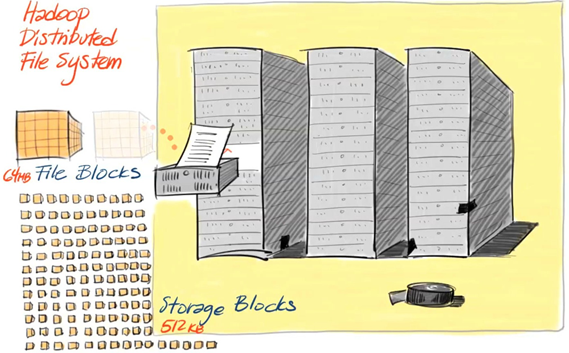 Source:Pivotal.io
“HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.” Hadoop by default stores 3 copies of each data block in the cluster on different nodes of the cluster. Any time a node or machine fails containing a certain block of data, another copy is created on another node in the cluster thus making the system fail proof.
Let me explain this statement.
“Very large” in this context means files that are hundreds of megabytes, gigabytes or terabytes in size. There are Hadoop clusters running today that store petabytes of data.
“Streaming data access.”
HDFS follows a write-once and read-many-times pattern. A dataset is generated or copied from the source, and then various analysis is performed on the dataset. Each analysis will involve a large proportion of the dataset, if not all, of the dataset, so the time to read the whole dataset is important than the latency (delay from the input into a system to the desired outcome) in reading the first record.
“Commodity hardware.”
Hadoop doesn’t require expensive hardware. It is designed to run on clusters of commodity hardware (a commonly available hardware that can be purchased from multiple vendors for which the chance of node failure across the cluster is high, at least for large clusters. HDFS is designed to handle such node failures.
Source:Pivotal.io
“HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.” Hadoop by default stores 3 copies of each data block in the cluster on different nodes of the cluster. Any time a node or machine fails containing a certain block of data, another copy is created on another node in the cluster thus making the system fail proof.
Let me explain this statement.
“Very large” in this context means files that are hundreds of megabytes, gigabytes or terabytes in size. There are Hadoop clusters running today that store petabytes of data.
“Streaming data access.”
HDFS follows a write-once and read-many-times pattern. A dataset is generated or copied from the source, and then various analysis is performed on the dataset. Each analysis will involve a large proportion of the dataset, if not all, of the dataset, so the time to read the whole dataset is important than the latency (delay from the input into a system to the desired outcome) in reading the first record.
“Commodity hardware.”
Hadoop doesn’t require expensive hardware. It is designed to run on clusters of commodity hardware (a commonly available hardware that can be purchased from multiple vendors for which the chance of node failure across the cluster is high, at least for large clusters. HDFS is designed to handle such node failures.
MapReduce Programming Model
The second problem is that most analysis techniques need to be able to combine the data in some way. Like, data from disk one may need to be combined with the data on disk four which in turn may need to work with data on disk 8 and 15. Combining data from different disks on the fly during the analysis can be a challenging task. MapReduce provides a programming model that makes combining the data from various hard drives a much easier task. There are two parts to the programming model – the map phase and the reduce phase—and it’s the interface between the two where the “combining” of data occurs.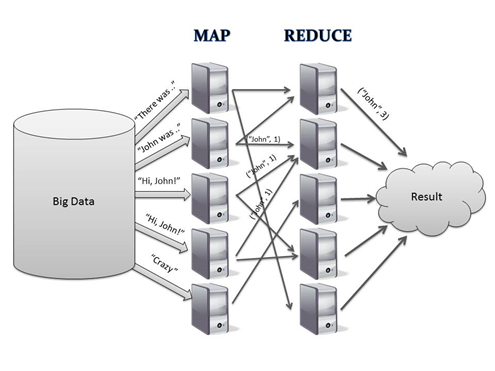 Source: DME
MapReduce enables anyone with access to the cluster to perform large-scale data analysis. Mapreduce has another benefit in that it moves the computing algorithm to where the data is stored instead of moving the data to the place where the computation has to occur. This saves tremendous amount of time and bandwidth which would have been spent in moving the tons of data from storage to computation.
MapReduce is a good fit for problems that need to analyze the whole dataset in a batch fashion, but it is not suitable for interactive analysis – you can’t run a query and get back answers in a few seconds or less. Responses to queries can take minutes or more, so MapReduce is better for offline use (where a human isn’t waiting for the answer to the queries).
Source: DME
MapReduce enables anyone with access to the cluster to perform large-scale data analysis. Mapreduce has another benefit in that it moves the computing algorithm to where the data is stored instead of moving the data to the place where the computation has to occur. This saves tremendous amount of time and bandwidth which would have been spent in moving the tons of data from storage to computation.
MapReduce is a good fit for problems that need to analyze the whole dataset in a batch fashion, but it is not suitable for interactive analysis – you can’t run a query and get back answers in a few seconds or less. Responses to queries can take minutes or more, so MapReduce is better for offline use (where a human isn’t waiting for the answer to the queries).
How Hadoop Implements MapReduce and HDFS
Hadoop uses both MapReduce and HDFS to solve both the problems described above. In the first problem. Hadoop distributes and replicates the dataset across the multiple nodes efficiently. So that if any of the nodes fail in the Hadoop ecosystem, it will still return the dataset appropriately. This is done efficiently using HDFS. In the second problem. Hadoop distributes the data across multiple servers. Each and every server offers the ability to analyze and store the data locally. When you run a query on a large dataset, every server in this network will execute the query on its local server on the local dataset. Finally, the results from all the local servers are consolidated. The consolidation part is handled effectively by MapReduce. For that reason, Hadoop uses MapReduce as its programming paradigm. Conclusion Hadoop now refers to a larger ecosystem of projects, not just HDFS and MapReduce, which falls under the category of distributed computing and large-scale data processing. Hadoop has transformed into a massive system for distributed parallel processing of huge amounts of data. MapReduce was the first way to use this operating system, but now there are other Apache open source projects like Hive, Pig, Spark, etc. Hadoop is written in Java, but it can run applications written in various programming languages (Python, Ruby, Scala, etc.). In a nutshell, Hadoop provides a scalable and reliable platform to store and analyze data. Our Certified Hadoop & Big Data Expert course will train you on big data analytics using the Hadoop framework.Edvancer Support
CEO at Edvancer
Latest posts by Edvancer Support (see all)
- Amit Thakur - June 11, 2020
- Nilisha Chhatbar - June 11, 2020
- Kaushik Jagini - June 10, 2020
Follow us on
Free Data Science & AI Starter Course
