Edvancer's Knowledge Hub
4 Hadoop Job Roles & Their Pre-requisites

Analyticsbig databig data analyticsBig data courseBig data jobsBig Data trainingdata scienceData science courseHadoopHadoop courseHadoop jobsHadoop pre-requisitesHadoop rolesHadoop training
If you are new to Hadoop & Big Data you must be wondering what the various Hadoop job roles entail, which one you would be most suitable for and what do you need to do to get one of those jobs.
Datameer’s has predicted the global Hadoop market to be $50.2 billion by 2020.

Share this on
Follow us on
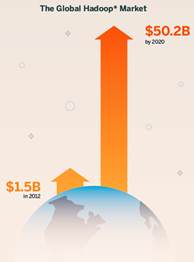
Source: Datameer
Even though the growth of the Hadoop market is high, Gartner survey shows that lack of skilled Hadoop professionals is the primary problem companies are facing in investing more. Companies are unable to find skilled professionals who know how to derive value from Hadoop. The above statistics shows that there is increasingly huge demand and supply gap for Hadoop professionals. Let us break down what the various Hadoop job roles are and what are their key pre-requisites in terms of skills:Building blocks of Hadoop
Apache Hadoop was a subproject of the web-search software called Nutch. The team at Nutch used Java to build Hadoop. Just because the team at Nutch were more comfortable to program in Java, they used Java to develop Hadoop – So there was no particular reason to use Java. Even though Hadoop can run on windows, it was built on Linux and it is the preferred method for installing and managing Hadoop. A fundamental knowledge of Linux (an operating system) can help you to understand the Hadoop ecosystem much better. Linux knowledge will also help you to work efficiently with HDFS (a distributed file system of Hadoop).Analysis of Hadoop Job market
I will show you three examples of Hadoop job positions and skills companies are looking while hiring for these positions. The following are not a complete list of Hadoop postings, but these just a few examples.- Hadoop Developer
- Data Warehouse Analyst/ ETL developer using Hadoop
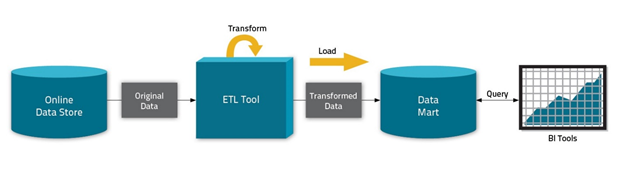
Source: Cloudera
Cloudera shows the three most common use cases for Hadoop ( data transformation, archiving, and exploration) – Many analysts say that more than 75 % of the Hadoop adoption resides in the first two use cases. If you are aiming to become an ETL developer/ a data warehouse analyst using Hadoop, then you need to have a strong knowledge of database and SQL concepts. Java programming is not a prerequisite to becoming an ETL developer/ a data warehouse analyst, but a fundamental knowledge of Linux will be useful.- Data scientist– Hadoop
- Hadoop Administrator:
Conclusion
Many articles in the big data community say that Java is not a prerequisite for two reasons:- Tools like Hive and Pig that are built on top of Hadoop offer their own programming languages, Pig can be programmed using Pig Latin and Hive can be programmed using HiveQL, for working with data on your cluster. So you don’t need to learn Java to use tools that are built on top of Hadoop.
- You can write MapReduce code in any language of your preference. There are specific APIs that converts your code written using any programming language (either C, Python or C++) to Java MapReduce code. So you don’t have to learn Java to program MapReduce.
Edvancer Support
CEO at Edvancer
Latest posts by Edvancer Support (see all)
- Amit Thakur - June 11, 2020
- Nilisha Chhatbar - June 11, 2020
- Kaushik Jagini - June 10, 2020
Follow us on
Free Data Science & AI Starter Course
