Edvancer's Knowledge Hub
Data Science Jargon Explained Simply!

AnalyticsAnalytics coursesAnalytics traininganalytics training institutebig databig data analyticsbusiness analyticsbusiness analytics coursebusiness analytics trainingdata scienceData science courseEdvancerHadoopHadoop courseHadoop training
If you are new to data science or to the big data industry, understanding complex jargon that dominates the industry can be difficult and overwhelming. With words like predictive analytics, machine learning, data munging and acronyms like IOT thrown casually in conversations, it’s easy to feel left out.
Have no fear, most commonly used data science terms explained in simple English are here!
 Source: The Executive’s Guide to Big Data & Apache Hadoop written by Robert D. Schneider; Page 9
Now we have only mentioned the most widely used terminologies in data science. Being the vast field that it is, there are many more! Are there any important phrases I’ve missed out on, that you’d like me to explain?
Let me know in the comments below, and we’ll definitely try to explain them simply!
Source: The Executive’s Guide to Big Data & Apache Hadoop written by Robert D. Schneider; Page 9
Now we have only mentioned the most widely used terminologies in data science. Being the vast field that it is, there are many more! Are there any important phrases I’ve missed out on, that you’d like me to explain?
Let me know in the comments below, and we’ll definitely try to explain them simply!
Share this on
Follow us on
Structured and un-structured data
Simply put, structured data can be sorted into rows and columns easily, and hence processed by data mining tools. Unstructured data on the other hand, does not fit in a traditional row-column data base, and often includes text and multimedia content. The snap shot below is an example of the difference between the two: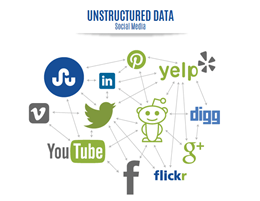
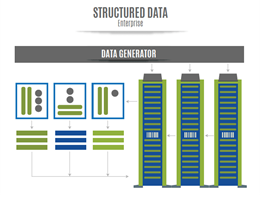 Source: The Executive’s Guide to Big Data & Apache Hadoop written by Robert D. Schneider; Page 9
Source: The Executive’s Guide to Big Data & Apache Hadoop written by Robert D. Schneider; Page 9
Analytics
It refers to the analysis of data to bring out the business insights from it. While the term analytics is used very loosely these days to refer to any kind of data analysis, it ideally refers to analysis of data using statistics and technology. It typically focuses more on structured data.Business intelligence
It is the process of analyzing historical data to derive insights that help executives and managers make more informed business decisions. The key difference between analytics and BI is that the former is used to predict the future, while the latter provides knowledge about the past situation only. Creating reports, dashboards etc. is part of BI.Data Science
Simply put, data science is the science that studies large amounts of data in an effort to make sense out of it. It requires an understanding of machine learning, big data architecture & analysis, advanced statistics, statistical tools like R and SAS or Python and software development. It is the umbrella science which amalgamates almost all of the other terms in this post. See our Data Science coursesStatistical model
A statistical model is a representation of some real-world phenomena but using mathematical equations. Most statistical models deal with finding the relationship between independent variables of the data to predict the outcome or the dependent variable of the data.Predictive analytics/Business Analytics/Predictive modeling
Predictive analytics or business analytics uses techniques from data mining, statistics, machine learning and artificial intelligence to analyze current & historical data and make predictions. A predictive model is usually nothing but a statistical model or a machine learning algorithm. Predictive analytics is used to drive strategic decision making by identifying trends, helping to understand customers better, predicting behavior, predict events etc. Learn Business Analytics here.Machine learning
Machine learning is a subfield of computer science that teaches a computer to learn from experience & fresh data, without having to manually program the computer each time. Machine learning algorithms teach computers to make and improve predictions or behaviors based on new data. Think self-driving cars or recommendation on e-commerce sites.Big data
Let us be frank. It is very difficult to define what exactly big data is and what is not! However to keep it simple it typically refers to data which is obviously large in volume (thing TBs and PBs), varied in format (text, numbers, audio, video, generally unstructured data etc.) and also have the property of being generated quickly (think tweets, status updates, mobile app usage, weblogs etc.). It could also be data that has significant issues in it and needs to be processed extensively to be made suitable for analysis. Hence big data would be something which requires a lot of fast processing power. Big data would typically exceed the processing capacity of traditional data base systems and conventional data base architectures and hence requires specialized frameworks like Hadoop & Spark to work with.Hadoop
Hadoop is an open source framework that lets you store, process and analyze huge volumes of data, both structured and unstructured, across a cluster of servers. Hadoop provides a distributed storage framework called HDFS and a computing algorithm to simultaneously process data across the cluster called Mapreduce. Take a look at our Hadoop & Big Data courseData munging/wrangling/cleaning
Data in real life has a lot of issues with having missing values, incorrect data, different formats, variables which need to be transformed into more usable form etc. It is the process of manually converting this raw messy data into an organized form which does not have missing values, incorrect values and has been transformed into data which can be used for statistical modeling. Remember garbage in, garbage out and hence data cleaning is important. Fun fact (that any data miner would not really find fun): Most data miners and scientists spend 50-70% of their time collecting and organizing complex data sets into a usable form.Text Mining
Text mining is the analysis of natural language textual data. The application of text mining techniques to is text analytics. Text mining usually involves structuring the unstructured input text data, cleaning it, understanding patterns in the structured data, and bringing out the business insights within it through statistical analysis and data mining techniques.Artificial Intelligence
Artificial intelligence (AI) is the intelligence exhibited by machines or software. It deals with creating devices/softwares that are capable of intelligent thinking & behavior just like a human. Think Deep Blue or Go.Internet of things (IOT)
IOT is the concept of connecting any electronic or mechanical device (cell phones, washing machines, wearable devices, sensors anything really) to the Internet or intranet. The objective is to collect & exchange data about the devices or the purpose of their usage in order to automate decisions regarding the physical world. Gartner claims that by 2020, there will be over 26 billion connected devices.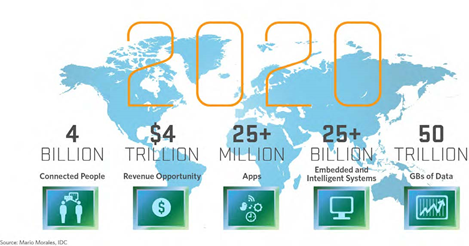 Now we have only mentioned the most widely used terminologies in data science. Being the vast field that it is, there are many more! Are there any important phrases I’ve missed out on, that you’d like me to explain?
Let me know in the comments below, and we’ll definitely try to explain them simply!
Now we have only mentioned the most widely used terminologies in data science. Being the vast field that it is, there are many more! Are there any important phrases I’ve missed out on, that you’d like me to explain?
Let me know in the comments below, and we’ll definitely try to explain them simply!
Edvancer Support
CEO at Edvancer
Latest posts by Edvancer Support (see all)
- Amit Thakur - June 11, 2020
- Nilisha Chhatbar - June 11, 2020
- Kaushik Jagini - June 10, 2020
Follow us on
Free Data Science & AI Starter Course
