Edvancer's Knowledge Hub
Any aspiring data scientist should know these Python libraries

Python has a unique combination of being both a capable general-purpose programming language as well as being easy to use for analytical and quantitative computing.
Python, along with R, is one of the handiest tools in a data scientist’s arsenal. It’s also one of the simplest computer languages to learn and use, primarily because most concepts can be expressed in fewer lines of code in Python, than in other languages.
Hence, beginners venturing out into the field of data science should definitely familiarise themselves with Python.
Python also offers a slew of active data science libraries and a vibrant community. Below are some of the most commonly used libraries and tools:
NumPy
NumPy is an open source extension module for Python. It provides fast precompiled functions for numerical routines. It’s very easy to work with large multidimensional arrays and matrices using NumPy.
Another advantage of NumPy is that you can apply standard mathematical operations on an entire data set without having to write loops. It is also very easy to export data to external libraries that are written in low-level languages (such as C or C++), and for data to then be imported from these external libraries as NumPy arrays.
Even though NumPy does not provide powerful data analysis functionalities, understanding NumPy arrays and array-oriented computing will help you use other Python data analysis tools more effectively.
SciPy
SciPy is a Python module that provides convenient and fast N-dimensional array manipulation. It provides many user-friendly and efficient numerical routines, such as routines for numerical integration and optimization. SciPy has modules for optimization, linear algebra, integration and other common tasks in data science.
Matplotlib
Matplotlib is a Python module for visualization. Matplotlib allows you to quickly make line graphs, pie charts, histograms and other professional grade figures. Using Matplotlib, you can customise every aspect of a figure. When used within IPython notebook, Matplotlib has interactive features like zooming and panning. It supports different GUI backends on all operating systems, and can also export graphics to common vector and graphic formats like PDF, SVG, JPG, PNG, BMP, GIF, etc.
Scikit-Learn
Scikit-Learn is a Python module for machine learning built on top of SciPy. It provides a set of common machine learning algorithms to users through a consistent interface. Scikit-Learn helps to quickly implement popular algorithms on datasets. Have a look at the list of algorithms available in Scikit-Learn, and you will realise that it includes tools for many standard machine-learning tasks (such as clustering, classification, regression, etc.).
Pandas
Pandas is a Python module that contains high-level data structures and tools designed for fast and easy data analysis operations. Pandas is built on NumPy and makes it easy to use in NumPy-centric applications, such as data structures with labelled axes. Explicit data alignment prevents common errors that result from misaligned data coming in from different sources.
It is also easy to handle missing data using Python. Pandas is the best tool for doing data munging
Theano
Theano is a Python library for numerical computation, and is similar to Numpy. Some libraries such as Pylearn2 use Theano as their core component for mathematical computation. Theano allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently.
NLTK
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources. such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, and wrappers for industrial-strength NLP libraries. NLTK has been used successfully as a platform for prototyping and building research systems.
Statsmodels
Statsmodels is a Python module that allows users to explore data, estimate statistical models, and perform statistical tests. An extensive list of descriptive statistics, statistical tests, plotting functions, and result statistics are available for different types of data and each estimator.
PyBrain
PyBrain is an acronym for “Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network”. It is an open source library mainly used for neural networks, reinforcement learning and unsupervised learning.
Neural network forms the basis for this library, making it a powerful tool for real-time analytics.
Gensim
Gensim is a Python library for topic modeling. It is built on Numpy and Scipy.
The figure below summarizes the number of GitHub contributors to the most popular data science libraries.
 These are some of the best libraries I’ve tried or come across. But there are others.
Would you add any other libraries to this list? Do you have experience with any of these? Share your thoughts with the rest of us!
These are some of the best libraries I’ve tried or come across. But there are others.
Would you add any other libraries to this list? Do you have experience with any of these? Share your thoughts with the rest of us!

Share this on
Follow us on
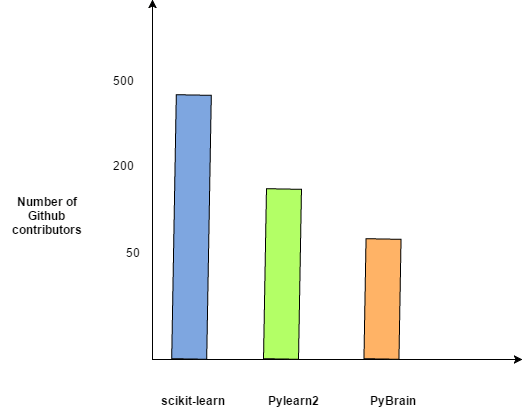 These are some of the best libraries I’ve tried or come across. But there are others.
Would you add any other libraries to this list? Do you have experience with any of these? Share your thoughts with the rest of us!
These are some of the best libraries I’ve tried or come across. But there are others.
Would you add any other libraries to this list? Do you have experience with any of these? Share your thoughts with the rest of us!
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
