Edvancer's Knowledge Hub
10 Free Data Science Programming Languages You should know
AnalyticsAnalytics coursesAnalytics traininganalytics training institutebig databig data analyticsbusiness analyticsbusiness analytics coursedata scienceData science courseData science programming languages
You cannot play tennis without a tennis racquet, or soccer without a football. Data science is a sport too, and you cannot play it without the right set of the tools.
I’m going to give you a go-to collection of the most commonly used data science software/ tools. They are intuitive, effective, powerful, and — best of all — they’re absolutely free.
R
R is a widely used programming language in the data science community. You can install R pretty easily, using R studio.
Previously, R was considered to be a data analysis language for statisticians, but it’s now widely used by Wall Street traders and Silicon Valley companies like Google, Facebook.
Once installed, you can analyze complex data sets, develop sophisticated data models, and create sleek graphics to represent your numbers, all in just a few lines of code.
The R community is very active and vibrant, and more than 2 million people use R.
Learn R programming from Edvancer.
Python
Python is a general purpose, intuitive and easy to learn programming language. It has many famous data analysis libraries like Numpy, Pandas, Scipy, Scikit-Learn, which makes it popular in the data science community.
I would recommend you use Ipython notebook as your programming environment to perform data analysis in Python. You can either install Anaconda or Enthought Canopy ; both these packages come with pre-installed libraries.
Famous banks like Bank of America and JP Morgan use Python to build new products and crunch financial data.
 The Weka workbench provides three main ways to work on your machine learning/ data mining problem: The Explorer, for playing around and trying things out; the Experimenter, for controlled experiments; and the KnowledgeFlow, for graphically designing a pipeline for your problem.
You can learn how to use Weka from this online course .
KNIME
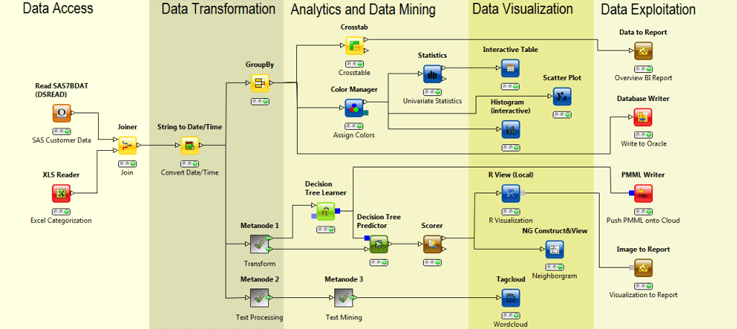
KNIME is an open source data analysis, predictive analytics, and modeling tool. It is not based on a scripting language. Instead, it has a GUI. You can model your data mining workflows using individual steps, each of these steps is called nodes.
KNIME provides a GUI that allows assembly of nodes for data preprocessing, data modeling, data analysis, and data visualization.
KNIME allows users to visually create data flows, selectively execute some or all analysis steps, and inspect the results, models, and interactive views. KNIME integrates various other open source projects, like machine learning algorithms from Weka, the statistics package R project, etc.
Conclusion
You need not learn all these programming languages/ tools to become a data scientist. But you need to know how these tools/programming languages are used, why they are used, their functionalities, which communities are using these tools, etc.
It seems unfair to compare these tools because each one of these tools has their own advantages and disadvantages!
What other free data science software/tool do you find useful? Drop a comment below!
The Weka workbench provides three main ways to work on your machine learning/ data mining problem: The Explorer, for playing around and trying things out; the Experimenter, for controlled experiments; and the KnowledgeFlow, for graphically designing a pipeline for your problem.
You can learn how to use Weka from this online course .
KNIME
KNIME is an open source data analysis, predictive analytics, and modeling tool. It is not based on a scripting language. Instead, it has a GUI. You can model your data mining workflows using individual steps, each of these steps is called nodes.
KNIME provides a GUI that allows assembly of nodes for data preprocessing, data modeling, data analysis, and data visualization.
KNIME allows users to visually create data flows, selectively execute some or all analysis steps, and inspect the results, models, and interactive views. KNIME integrates various other open source projects, like machine learning algorithms from Weka, the statistics package R project, etc.
Conclusion
You need not learn all these programming languages/ tools to become a data scientist. But you need to know how these tools/programming languages are used, why they are used, their functionalities, which communities are using these tools, etc.
It seems unfair to compare these tools because each one of these tools has their own advantages and disadvantages!
What other free data science software/tool do you find useful? Drop a comment below!

Share this on
Follow us on
Learn how to use Python for data science from Edvancer.
Julia Normally, data geeks use one programming language (like R, Python, etc.) to prototype a predictive model and another programming language (like C, C++) to make the model faster. You need to learn two or three programming languages, write a significant amount of code and switch between different code editors and source files to deploy a working predictive model. This is a cumbersome task, and takes more time than any data scientist can afford to waste. In Julia, you can write code with the performance of C so that you don’t have to rewrite its code in a low-level language (like C, C++). Julia’s only drawback at this point is a dearth of libraries – but Julia makes it easy to interface with existing C libraries. I encourage you to download Julia and use it, it has an active and supportive community. Hadoop Hadoop platform was designed to solve problems where you have a lot of complex data sets that doesn’t fit into a traditional relational database. Hadoop is a distributed file system (HDFS) — with multiple nodes/servers– that helps businesses store unstructured data in vast volumes, at speed and on commodity hardware, at a very low cost. HDFS uses a programming model called Map Reduce to access and analyze the data in it. Map reduce process all the data on all the nodes.Get a globally recognized certificate in Hadoop from Edvancer and Wiley.
Apache Spark Spark, the open-source cluster computing framework, is best known for its ability to keep large working data sets in memory between jobs. This capability allows Spark to outperform the equivalent MapReduce workflow, where datasets are always loaded from a disk. It also provides a rich set of APIs to perform common data analysis tasks, such as Joins, which makes it easier to learn and program when compared to MapReduce. Spark provides APIs in three languages: Scala, Java, and Python. SQL SQL (structured query language) is used to query and edit information stored in a relational database. A relational database is used to store structured data. As a data scientist, you should write code in SQL or something similar (Hive) to pull the data into R, Python or whatever tool you use to analyze data. SQL is a pretty simple language, and I would recommend the course by Bucky Roberts to learn the basics of SQL. D3.JS Data visualization is the idea of conveying a story as visually as possible. Data scientists use data visualization to explore patterns in the data and to ultimately convey the results to stakeholders. D3.js is a javascript library for producing dynamic and interactive data visualizations in web browsers. But it is not a graphics or a data processing library, it doesn’t have inbuilt charts that limit creativity. Instead, it has functionalities that make the connection between data and graphics easy. D3.Js works seamlessly with front-end web technologies like HTML, CSS, and SVG. Great documentation, examples, community and the accessibility to Mike Bostock (Key developer of D3.Js) have all played major roles in increasing the popularity of D3.js. Octave GNU Octave is an open source programming language used to perform complex numerical computations such as linear and nonlinear problems. Octave is quite similar to Matlab and is often considered as the free alternative to Matlab. Octave also provides extensive graphical capabilities to visualize and manipulate data. It is normally used through its command line interface. A good way to learn Octave is through Coursera’s Machine Learning course. Weka Weka (Waikato Environment for Knowledge Analysis) is an open source data mining software written in Java. It has a GUI that lets you execute your machine learning projects without writing a single line of code. I encourage you to download and experiment with Weka. You might have to install Java before installing Weka.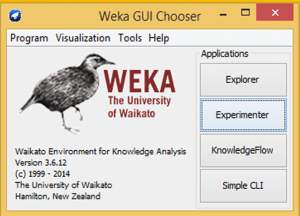 The Weka workbench provides three main ways to work on your machine learning/ data mining problem: The Explorer, for playing around and trying things out; the Experimenter, for controlled experiments; and the KnowledgeFlow, for graphically designing a pipeline for your problem.
You can learn how to use Weka from this online course .
KNIME
KNIME is an open source data analysis, predictive analytics, and modeling tool. It is not based on a scripting language. Instead, it has a GUI. You can model your data mining workflows using individual steps, each of these steps is called nodes.
KNIME provides a GUI that allows assembly of nodes for data preprocessing, data modeling, data analysis, and data visualization.
The Weka workbench provides three main ways to work on your machine learning/ data mining problem: The Explorer, for playing around and trying things out; the Experimenter, for controlled experiments; and the KnowledgeFlow, for graphically designing a pipeline for your problem.
You can learn how to use Weka from this online course .
KNIME
KNIME is an open source data analysis, predictive analytics, and modeling tool. It is not based on a scripting language. Instead, it has a GUI. You can model your data mining workflows using individual steps, each of these steps is called nodes.
KNIME provides a GUI that allows assembly of nodes for data preprocessing, data modeling, data analysis, and data visualization.
 KNIME allows users to visually create data flows, selectively execute some or all analysis steps, and inspect the results, models, and interactive views. KNIME integrates various other open source projects, like machine learning algorithms from Weka, the statistics package R project, etc.
Conclusion
You need not learn all these programming languages/ tools to become a data scientist. But you need to know how these tools/programming languages are used, why they are used, their functionalities, which communities are using these tools, etc.
It seems unfair to compare these tools because each one of these tools has their own advantages and disadvantages!
What other free data science software/tool do you find useful? Drop a comment below!
KNIME allows users to visually create data flows, selectively execute some or all analysis steps, and inspect the results, models, and interactive views. KNIME integrates various other open source projects, like machine learning algorithms from Weka, the statistics package R project, etc.
Conclusion
You need not learn all these programming languages/ tools to become a data scientist. But you need to know how these tools/programming languages are used, why they are used, their functionalities, which communities are using these tools, etc.
It seems unfair to compare these tools because each one of these tools has their own advantages and disadvantages!
What other free data science software/tool do you find useful? Drop a comment below!
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
